BYOW 项目复盘
BYOW 项目复盘
声明
本博客需要的前置知识:数据结构、 Java 基本知识
本篇博客是对于 UCB CS61BL 课程中的 Project 3 进行复盘和反思,项目介绍与项目地址可以点击此处抵达。
根据课程的政策,我不会在本篇博客中展示我项目中的任何代码以及底层实现,此博客仅仅从项目的高层设计思想和相关知识点展开,作为自我学习的留档。
如果想要对这个项目有一个初步的了解,可以参考这个链接。
需要完成什么
BYOW 是 Build Your Own World 的简称,我们最终的目标是构建一个随机生成的二维世界,其中有一个标志代表玩家,同时玩家可以通过 WASD 对玩家的位置进行控制,从而对于世界进行探索。

在此基础上,我们还需要实现一个目录,这个目录可以达成游戏的开始,载入,退出等功能。

渲染框架
为了实现这样的效果,我们需要一种可以将代码转化成可以在显示器上显示的方式。在系统的内部,IO总线将每一帧通过数据流输出到显示器,显示器把数据流再转换成具有色彩信息的图像输出。
我们不需要从零实现这些,这个过程涉及诸多计算机的架构互相协作,不过好在这些工作别人都已经帮我们封装好了,在这个项目中,我们使用普林斯顿大学编写的 StdDraw 库,这个库可以渲染出一个如上的界面。
哪怕在实际的游戏开发中,我们一般也不需要从零去构建这些功能,游戏引擎可以帮我们完成这一部分。
世界构建
现在我们聚焦于如何去构建这样一个世界,包含不同的长方形房间和转弯的走廊。
首先,我们先明确自己的需求,这个世界主体是由房间和走廊形成的,房间尺寸大于 2*2 ,由墙包裹。走廊宽度为 1 或 2 ,同样有墙包围,整个世界中应该有至多 80% 的走廊为直走廊。
第一个想法 —— BSP
生成空间
通过在网络上搜索,我们找到了一种名为 Basic BSP Dungeon generation 的生成方式。如同其字面含义,这种生成方式用到了 BSP。
In computer science, binary space partitioning (BSP) is a method for space partitioning which recursively subdivides a Euclidean space into two convex sets by using hyperplanes as partitions. This process of subdividing gives rise to a representation of objects within the space in the form of a tree data structure known as a BSP tree.
这种方法的核心在于通过一种树的结构,将整块二维空间视作树的根,然后随机选择竖向分割还是横向分割,并且随机决定分割位置,接着将分割后的两片空间作为子树的根。递归进行这个过程,我们就可以使用二叉树来分割出空间。
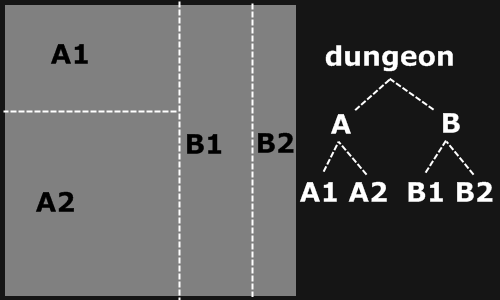
在这种情况下,该树的所有叶节点即为最小单位,但是有一个问题:划分到什么程度我们可以开始下一步呢?
有两种大致的模式:一种是通过限制一片空间的最小面积,这种方法下,我们得到的是二叉树的子树高度不一定相同。另一种方法是限制树的高度,这样一定可以得到一个完全二叉树,但是对于树的高度与空间大小之间的关系需要通过设置数个空间大小限制变量以生成合法的空间。
生成房间和走廊
在上述空间的基础上,我们遍历每个叶节点,随机生成两个数代表房间的宽和高,宽和高要小于 空间宽度 - 2 和 空间高度 - 2 。随后再生成房间在这个空间中的位置,同样要注意随机数的生成范围。
然后我们将二叉树的所有具有同样父节点的子树通过走廊连接起来。这是因为同样父节点的节点对应了 BSP 中对同一片空间的分割,那么这两个节点一定是相邻的,而对于非叶节点之间,同样代表相邻的空间,而我们的目标是用走廊连接不同的房间,这一点差别需要我们考虑在具有多个房间得到空间是需要再次考虑对于两个空间,应该用空间中的哪个房间连接哪个房间。
同样这种方法比较难以处理带有转弯的走廊,对于两个相邻空间,需要将所有房间内空间纳入考虑,这对于之后的数据结构构建具有较大的难度。一种处理方法如下:

对于空间 A 和空间 B ,在所有墙壁内的空间中随机挑选一个点,使用一种路径搜索算法搜索两个点之间的最短路径,使用走廊连接。
几个缺点
过于繁琐的数据结构
树内部使用的算法大量使用递归,使算法没有那么直观。同时从 空间 到 房间 再到 房间 + 走廊 ,提升了数据结构的复杂度。
对于转弯走廊的欠缺
因为走廊要求带有转折,在这种设计下转折全靠运气,同时这个概率不高,因为走廊总是生成在两个相邻的空间。
世界还是地牢?
世界并不像地牢那样有明确的生成规律,通过抛弃一定的规律性去追求代码上的简洁是值得的,反而可能生成出带有奇观的世界。
这几个缺点和较短的开发时间促使我抛弃了这种算法,转向一种更简单的生成方式。
第二个想法 —— 随机投掷
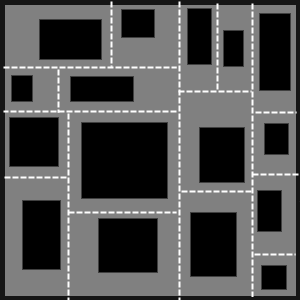
第二个想法和第一个想法相比就要简单的多了。核心思路是直接对整块空间投掷房间,如果在当前位置已经存在一个房间了,那么就跳过当前房间再次进行投掷,直到投掷的房间数量达标。
然后随机挑选两个房间,使用走廊将这两个房间连接,不需要担心走廊会会穿过其他房间,因为只要走廊使用的地板和房间的地板相同,那么走廊是否穿过房间就是无法被识别的。
而走廊生成时的起始位置和终点也直接在房间内进行点的投掷,以最短路径进行连接即可。

在上述图像中,我们在房间 A 和房间 C中分别随机挑选一个点,然后通过直角最短路径连接,其中虽然穿过了房间 B ,但是并不影响这个世界由走廊和 房间构成,我们依旧可以把这一条走廊拆开成从房间 A 到房间 B 和从房间 B 到房间 C 的两条走廊。这种模式下虽然不存在明确的房间与走廊的对应关系,但是满足我们想要生成世界的基本条件。
内部的数据结构
接着我们对需要的数据结构进行讨论。首先我们可以把世界的生成分成两个部分:
- 房间
- 走廊
而更具体的以及更加底层的是构成房间和走廊的点,房间可以看作由左下角和右上角两个点组成的一片空间,而走廊是由起点和终点两个点定义的一个折线。点更进一步应该是由 X 轴坐标和 Y 轴坐标组成。
用对象代替变量
思考一下两种实现方式哪一种更好:
1 | // 以 a 点为左下角, b 点为右下角生成一个房间 |
1 | // 以 a 点为左下角, b 点为右下角生成一个房间 |
这两种实现方式的唯一区别是函数的参数输入是使用 Point 对象还是直接使用函数值,对于我而言,前者是一种更好的代码风格。
首先,这是符合面向对象编程的核心思想:抽象。所有现实中的物体都可以被抽象成一个个类,从类的外部,能够看到的只有已经定义好的接口,内部对于外部是一个黑箱,因为我不需要也不希望知道每个黑箱的内部实现方式。这种模式的目的在于解耦合,即将代码之间相互的依赖性处理的相对简单,每一个模块之间都可以相互分离。
从这种思想我们又可以引申出一种软件设计模式,自顶而下。这种设计模式要求我们先从顶层——最宏观的需求出发,先构建出一个框架,然后在这个框架之下进行搭建,在框架下我们不需要关心宏观的框架,转而聚焦于微观的代码编写。
在当前这个项目中,我们先明确了软件的目标,然后找到了我们需要哪些类,即点,房间,走廊。有一个世界类,存储整个世界的信息,当然还有一些额外用于管理和提供方法的类,会在后文进一步展开。最后聚焦于每一个类内部如何编写,这就是自顶向下的设计模式。
随机性的实现
在这一节最后讨论一下随机的问题。在计算机中所有的随机都是伪随机,只要条件相同,那么重复的结果是相同的,所以在这个项目中,我们使用了一个 Random 类的实例用来生成随机数。
在这个项目中,我们有如下几个需要用到随机的地方:
- 生成房间的位置
- 随机选择房间,为房间加上走廊,直到所有房间联通
- 生成走廊的位置
- 随机生成玩家位置
只看表面似乎没有什么问题,但我们需要保证所有的随机数都是由同一个 Random 类的实例生成的,一旦引入了其他带有随机性的类,那么在不知道内部的实现方法时,这种方式是带有风险的。比如 Java 中的 HashTree 为了保证树的平均以保证 O(logN) 的算法复杂度,这个类中会引用随机类生成随机数,而这个随机类实例的种子并不是由我们自己编写的种子生成的,我们无法保证每一次运行都得到同一种成果。
在上述过程中容易出问题的是第二步,如果我们将房间当作节点,那么房间和走廊的关系就如同节点和边的关系,那么我们可以使用集合的数据结构来生成走廊。在这种情况下,如果在集合的实现中使用 HashTree ,那么就会导致同一个种子下每一次生成的边并不固定,当然这并不说明这种生成方式是真随机,只是因为我们不知道随机数的种子导致了我们无法复现。
为什么这种随机方式会导致每次重复时不同?在我们生成地图的时候,会要求玩家输入一个种子,这个种子在世界初始化时作为构建 Random 实例的参数使用,也就是说,只要使用同样的种子,那么在世界初始化时产生的 Random 实例就是相同的,那么通过调用它生成的一系列随机数序列也是相同的。而如果没有种子呢?在 Random 实例的构建时,我们可以不使用参数作为种子,但是因为封装,我们不知道 Random 类内部是怎样处理这种情况的,如果它使用一个固定值作为默认种子那程序不会出问题,但如果使用一些会随着运行改变的变量作为种子,比如说当前时间的时间戳,那么会导致不同种子的产生,进而影响随机性的实现。
状态管理器
到目前为止,我们已经搞定了世界生成的大部分问题,现在让我们讨论一些更加宏观的东西,比如如何构建游戏的框架,毕竟我们的程序并不仅仅需要实现生成一个世界就结束了,我们还需要使这个程序具有面向玩家的交互性。
状态管理器是什么
首先我们可以先定义什么是状态。比如说在如下的游戏菜单中,我们可以把它作为目录状态。
而我们按 N 键打算新建一个世界时,在生成世界之前,如下所示,需要有一个界面提示玩家输入世界的种子,这也是一种状态。

这样,我们大致就对于什么是状态有头绪了,状态,是为了区分有较大区别的功能模块之间的转换,举个简单的例子,在菜单状态下我按 N 键可以进入种子生成状态,在种子生成状态下再按 N 键就无法有任何反馈,因为状态切换了。那么同样的,统一对于状态进行管理的部分就称作状态管理器,接着我们会一步步构建项目管理器已经阐明为什么需要状态管理器。
不同功能的模块化
这里有一个例子:
1 | // 一个图书馆管理系统的功能跳转部分 |
这是一个图书馆管理系统,通过命令行参数传递进行运行,使用了 switch 分支选择实现了通过命令行参数执行不同的功能,我们不必要把所有的东西都塞在一个文件中,按照功能进行分类,然后在不同的文件中分别实现对于增加代码的可读性以及理清设计的脉络是有益的。
对于 C 语言来说,这是一种面向过程的语言。顾名思义,就是通过将代码执行的顺序通过认为的设计进行排布,从而实现程序的功能。而 Java 是一种面向过程的语言,我们将每一个模块抽象成对象,然后关注对象之间的交互。总的来说,面向对象的特性使我们可以更加容易的设计大架构的程序。
在我们当前的项目中,我们大致有这样的流程:

在上述流程的基础上,我们同样可以使用 Switch 的分支选择,但是这个时候就会遇到按键冲突的问题,接下来我们会通过将状态的继承和模块分离来完成这个模块。
状态和继承
想一想,我们上述讨论的状态有什么共性?其实最大的共性就是这些状态都有几个必须要有的操作,大概分为进入状态,更新状态,渲染状态以及离开状态,明白了这点,我们就可以定义出一个抽象类,这样就将上述的图所示循环进行了一定的更改。

这样我们就将程序变成了不同状态的转换;在前一个状态的 Exit() 中创建新状态的实例,在新状态的 Enter() 对各个变量进行初始化,状态由 Exit() 和 Enter() 首尾相连。
状态流程图
根据上述的思想,我们就可以画出这个程序的状态流程图了。

接着只要依次设计每个状态即可。
状态管理对象的变量传递
在状态管理的最后一段我会分析一下状态管理下的静态变量问题。
在这个程序运行过程中,有一些变量是始终不变的,比如在同一局游戏中,整个世界的变化应该是连续的,也就是说,不会出现本来运行着一个种子生成的世界,但是却突然变成了另一个种子生成的世界,这时就会出现跨状态的变量。
比如说在上述的流程图中,SeedInputState 会接收种子并且生成世界,同时这个世界和 PlayState 中的世界是相同的,如果这两个状态之间的关系只是函数互相调用的关系,也就是面向过程的设计模式,那么我们完全可以直接将包含世界信息的变量通过参数传递,但是既然我们已经定义了 State 的抽象类,那么我们就无法直接修改 Enter() 函数来满足我们传递参数的需求。
这个时候最简单的方法就是将这些变量作为静态变量放置在一个类中,比如 World 类,包含所有与世界相关的变量和函数,也自然可以通过静态变量储存世界信息,当一个状态需要相关的信息时,直接调用 World 类中的静态变量即可。
但是这样也会带来问题,为程序引入大量的静态非 Final 参数会拖慢程序的速度,这个时候就需要做出一定的取舍——我需要程序有更高的可读性还是有更好的性能。当然也有另一种的方式,即修改 State 抽象类,或者使用重载或对象的传递以更加优雅的方式定义不同状态之间的相同部分。
如何改变世界
当然,只是生成一个世界却不能与其进行交互是很无聊的,所以现在我们进入这个项目第二个阶段的任务,即生成世界后如何通过键盘和鼠标和已生成的世界进行交互。
键盘状态的更新
回想我们在上一节所所构建的这个程序运行过程,我们现在要处理的就是接收键盘指令这一步,我们在这里定义一个帧的概念,你可以将一帧视作一个循环,也就是上述红色框出的部分。
这里我们有两种处理方法,一种是只有在键盘输入了字符,我们再进行下一步处理,也就是只有当世界发生了改变后,才刷新一次画面,这种方法的优点在于较为节省性能。第二种方法是无论玩家是否通过输入设备与程序进行交互,这个循环始终运行着,并且不断刷新当前画面,在我们不设置帧数的上限时,这种方法会用光所有的性能,因为程序会尽量快的运行,此时游戏的帧数可以到千帧以上。
优化的方式很简单,只要在每一次循环时暂停一定的时间,就可以对于游戏的帧数进行限制,当然,这里面还会涉及到一个问题,就是暂停的时间和运行花费的时间总和才是完整的一帧,这意味着我们对于帧数的设置只是一个大概的值,而并不是精确值。如果我们需要精准的一个帧数,比如说 60 帧,那我们就不能简单的使用暂停实现。
模拟世界的更改
观察底层结构,世界的存储是通过一个二位数组实现的,二维数组的元素是贴片类中的静态量,通过不同的字符串表示不同的物体,所以只用简单的更改这个二维数组即可。需要注意的是,我们之前提到了在不使用非 Final 的静态量的情况下,一定会出现我们的世界随着状态进行传递,这种传递有可能会造成多个表示世界的二维数组同时存在,状态类和状态管理类的数组被混淆,所以进行更改时需要关注更改的是哪一个二维数组。
至于如何将不同的键位和不同的操作进行绑定,在不同状态类下的 Update() 函数中使用选择分支即可。
世界的保存
保存当前状态
直接保存当前状态就像是对当前状态拍了一张照片,待到再次进入游戏时,在从文件中提取出相应的信息,这是大部分游戏中会采取的方式,一个想法是通过构建一个保存类来保存所有数据,然后通过序列化的手段将这些数据都转化为字节码,在存储到文件中,具体的方法可以详见Gitlet项目复盘的对象序列化部分。
保存历史操作再还原
首先我们先观察已经提供的实用工具,在 utils 路径下的 FileUtil 类中。
1 | package utils; |
我们可以看到,它并没有像 Gitlet 项目中提供完整的序列化工具,只是提供了一个将字符串写入文件的工具。
同时在野心分数中提到的附加要求中,有一项是 replay ,要求游戏可以重播所有世界创建以来的操作。
所以这就引向了一种思路,对于游戏的操作是通过键盘输入的,那一定是一串字符串,我们只用将存储这串字符串即可,与正常进行游戏不同,我们在载入游戏的时候并不需要让玩家输入种子,而是直接从存储文件中读入种子,因为在第一次运行游戏的时候种子也被作为玩家在键盘上的输入被记录。
这里是一个模式匹配的问题,我们需要找到一个字符串中以 N 或 n 开头,以 S 或 s 结尾的第一个字符串,这个子串中的所有数字拼接在一起组成要加载的世界的种子。比如说记录中的字符串是 n1234sawsd ,那么很显然这个世界的种子就是 1234 。更复杂的例子包含一些键盘上的无效操作,考虑 asazsn12abba34swasdas 这一串中核心部分是 n12abba34s ,还需要剔除掉中间的无效操作 abba ,最后组合出正确的种子。这一部分关于模式识别,碍于篇幅问题在此就不再继续展开了。
最后我们只需要用和主程序类的方式把剩余字符串视为键盘输入流输入即可,不过在加载过程中我们不会调用状态的 Render() 和用于限制帧数的时间暂停,文件读取完毕后使程序进入 PlayState 即可,如果需要的话可以单独定义一个 LoadState ,专门用来处理加载世界的情况。
野心
其实到此处我们已经完成了这个项目的基本要求,不过为了使我们的小游戏更加完善,我们会为程序添加一些格外的功能,功能分为价值 8 分的主要功能和价值 4 分的次要功能,这里主要讨论主要功能。
旋转世界
这一项要求我们可以通过案件旋转世界的视角,如果你玩过饥荒,那最好的例子就是通过 e 和 q 键可以向左或向右旋转当前的方向。在我们的小游戏中,可以将代表整个世界的二维数组通过一个函数映射到一个新的二维数组上,这里的一种想法是线性代数的方式,我们通过对现有的二维数组坐标通过乘一个矩阵的方式来旋转整个二维数组。
除此之外,还需要考虑非正方形的空间中,会导致游戏的窗口发生改变,一种方法是重新渲染一个窗口,另一个方法是事先按照较长边为世界预留空间,在旋转时就不会受到长短边的影响。
战争迷雾
战争迷雾是游戏中常用的术语,常用于指代那些超出视线范围从而无法被看到的区域,比如在 星际争霸 或 英雄联盟 中,大量使用了这种元素,如果你想要进一步了解,可以点击这个链接进一步了解。
实现这一点,我们需要先设定哪一些区域是可以被看见的,最简单的一种就是人物的一定视线范围内的东西可以被看到,我们以这个举例。想一想,我们在实际渲染的时候是传递给渲染器一个贴片的二维数组,在实际的游戏设计中,我们可以对渲染器进行更改,在渲染每一个区域时先对于是否需要渲染进行判断。但在当前的项目中,我们只能传递二维数组,那么另一种方法就是把二维数组中我们看不见的区域在渲染之前就进行更改,比如说我们可以设置这些区域为 Nothing ,这样渲染出来的效果就是黑色的。

用对象抽象敌人与交互物
这个世界只有我们能动太无聊了!我们可以尝试去添加一些别的可以移动或交互的对象,比如说 NPC 或者是一些敌人,在设计这一部分的时候依旧遵循将实际的东西进行抽象,找出他们的共同特点,设计抽象类、接口,接着使用类似于渲染你自己的方式渲染每一个可移动对象或交互物。
如何让它们动起来?尝试使用 DFS 或 BFS 算法为这些交互物设计路径,让他们追逐目标。或者是每隔多少秒随机选择一个方向走一步。这一部分可以与后续的 CS188 进行衔接,设计一个智能体,可以躲避吃豆人的追击。

结语
至此,我们的游戏已经可以得到满分了,其中包含基础的世界生成、玩家与世界的交互以及野心得分,但是在项目之外,还有一些细节我想要和你去做一些探讨。
代码重构
重构,你可以将其理解为对代码的整体进行更改。在测试代码时,如果发现了一个 Bug ,并对其进行修改,这算不算重构?我想多半是不算的,因为重构更多侧重于顶层设计的更改。
你可能会想问,重构有什么用?既然已经实现了代码的功能,为什么还要进一步对其进行更改,主要代码能跑就行了。这种想法在制作一个小型的程序或者脚本的时候不会有太多的问题,但是一旦涉及到复杂的架构时,一定会使编程变得复杂,错误的概率变高,从而降低编程的效率。
比如说在这个项目中,如果我们不引入状态管理器,那么负责渲染的模块和负责完成内部功能的模块多半会耦合在一起,这对于代码的可读性是致命的打击。静态量和动态量也会混杂在一起,而且在添加其他状态时还要在状态之间的衔接上下大功夫,为不同的状态的入口和出口设计不同的接口,这很麻烦,违背了代码的规范,或者说哲学。
代码哲学
通过在 Python 解释器中输入 import this ,我们会得到如下的结果:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren’t special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one– and preferably only one –obvious way to do it.
Although that way may not be obvious at first unless you’re Dutch.
Now is better than never.
Although never is often better than right now.
If the implementation is hard to explain, it’s a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea – let’s do more of those!
这段话包含了在编写 Python 程序时 Python 希望开发者做到的准则。这不是强制要求,更多的是一种哲学上的规范,程序员总是希望自己的代码简洁且优雅。
如果你还想对于重构有更加深刻的理解,可以看一看这本书,或许会对你有所帮助。
再谈项目管理
最后一部分我想谈一谈项目管理,项目管理将多名开发者的力量结合起来,从而加快软件开发的效率。但是一个糟糕的项目管理,有可能会出现 1 + 1 < 2 的情况,这是因为编程作为一个有一定的技术门槛的技能,每一个人所掌握的都是不一样的,就好像两个人沟通的时候,如果使用不同的语言,那难免出现驴唇不对马嘴的情况。
项目管理的核心是分工,而为了达到分工的目的,势必要保持各个模块的解耦合。当一个开发者想要对其他开发者编写的代码进行复用的时候,不应该需要知道具体的实现,正如在 Gitlet 项目中提到的,在一个良好封装的结构中,除了接口外,程序的运行应当是一个黑箱。
在这个项目中,评分标准中强制要求两个人为一组共同进行开发,这个项目客观上相对于 Gitlet 项目是要简单的,因为允许使用大语言模型 ,并且对于底层的数据结构的要求没有那么严格,所以其实这个项目更像是通过合作完成一整个项目,从而体验在一个完整项目的项目管理。
当然,在实际的软件开发中,软件的复杂度要比这个小游戏复杂的多,在此基础上,随着团队的不断扩大,我们可以引入更加复杂的开发方式,比如瀑布开发,灵活开发等,不过万变不离其宗,保持代码的可读性,保持协作的简洁。



